Taxonomy of Embedded ML Frameworks
Choosing the Right Framework for Your Embedded ML Project
The embedded ML landscape is a fragmented ecosystem of overlapping tools, vendor-specific solutions, and open-source projects at varying levels of maturity. Engineers starting an embedded ML project face a bewildering array of choices: TFLite Micro, ExecuTorch, STM32Cube.AI, NXP eIQ, emlearn, hls4ml, and more. Each tool makes promises about performance, ease of use, and hardware support. Few explain when you should actually use them.
This guide provides a structured taxonomy of embedded ML frameworks. We'll categorize them by their core approach, map them to hardware tiers and application domains, and give you concrete decision criteria. The goal here isn't to crown a winner but to help you avoid spending three months on a framework that can't meet your requirements.
The Fundamental Split: Runtime Architecture
Every embedded ML framework falls into one of two architectural categories. Understanding this split is the first step to narrowing your options.
Interpreter-Based Runtimes
These frameworks deploy a model file alongside a generic inference engine that parses and executes the model at runtime.
- Examples: TensorFlow Lite Micro, uTensor
- Advantages: OTA model updates without firmware reflashing; flexibility for model experimentation
- Disadvantages: Runtime overhead (50-100KB for the interpreter); startup latency for model parsing; harder to achieve deterministic timing
Ahead-of-Time (AOT) Compilers
These tools compile the model directly into C/C++ source code that becomes part of your firmware binary.
- Examples: STM32Cube.AI (X-CUBE-AI), TVM/microTVM, Edge Impulse EON, emlearn, hls4ml
- Advantages: No runtime overhead; smaller Flash footprint; predictable execution timing; better optimization opportunities
- Disadvantages: Model updates require firmware rebuild and reflash; less flexibility during development
The choice between these architectures depends on your deployment model. If you need to push model updates to thousands of devices in the field without reflashing firmware, interpreter-based runtimes make sense. If you're optimizing for minimum footprint and deterministic latency, AOT compilation wins.
Framework Categories
Beyond the runtime split, embedded ML frameworks cluster into five functional categories. Each serves different needs and developer profiles.
1. Vendor-Specific Toolkits
These are integrated development environments provided by silicon vendors, optimized for their specific hardware.
Vendor: STMicroelectronics
Target: All STM32 MCUs, including NPU-equipped STM32N6
Input formats: TFLite, ONNX, Keras (.h5), scikit-learn via ONNX
Key features: Deep integration with STM32CubeMX; supports INT8 and deeply quantized networks (down to 1-bit); Neural-ART Accelerator support; built-in validation tools
Best for: Teams already in the STM32 ecosystem wanting turnkey deployment
Vendor: NXP Semiconductors
Target: i.MX 8M applications processors, i.MX RT crossover MCUs, MCX-N with Neutron NPU
Input formats: TensorFlow, ONNX, PyTorch
Key features: Multiple inference engine options (Glow, TFLite, Arm NN); eIQ Toolkit for model training/optimization; Time Series Studio for sensor data; NVIDIA TAO integration
Best for: NXP-based products requiring GPU/NPU acceleration or Linux-based edge computing
When to choose vendor toolkits: You've already selected your silicon and want the path of least resistance. Vendor toolkits offer the best hardware utilization for their specific chips, comprehensive documentation, and direct support channels. The tradeoff is lock-in—migrating to different silicon later will require significant rework.
2. AutoML/No-Code Platforms
These platforms abstract away model architecture decisions, letting engineers focus on data collection and deployment.
Vendor: STMicroelectronics
Target: Any Arm Cortex-M MCU (now free for all ARM Cortex-M)
Key features: Automatic algorithm selection via benchmark; anomaly detection, classification, regression, and extrapolation; on-device learning capability; synthetic data generation (v5); minimal dataset requirements
Best for: Teams without ML expertise; predictive maintenance and anomaly detection; rapid prototyping
Vendor: Edge Impulse Inc.
Target: Broad MCU support (Arduino, STM32, Nordic, Raspberry Pi, etc.)
Key features: End-to-end MLOps platform; data collection from devices; signal processing blocks; model optimization and quantization; deployment to 50+ hardware targets; EON compiler for AOT deployment
Best for: Startups and product teams wanting a complete TinyML workflow; audio/motion classification; teams needing data management infrastructure
When to choose AutoML platforms: You have domain expertise but not ML expertise. You need to iterate quickly on model architectures. You're working on time-series sensor data (vibration, audio, motion) where these platforms have strong pre-built signal processing blocks. The tradeoff is less control over model internals and potential performance gaps versus hand-tuned solutions.
3. Open-Source Inference Frameworks
Community-driven projects that prioritize portability and transparency.
Maintainer: Google / TensorFlow team
Target: Cortex-M and other bare-metal platforms
Key features: Interpreter-based runtime; broad operator coverage; integrates with CMSIS-NN for Arm optimization; well-documented; large community
Runtime size: ~50-100KB (interpreter + operators)
Best for: Projects requiring broad ecosystem compatibility; teams familiar with TensorFlow; applications needing OTA model updates
Maintainer: Meta (PyTorch team) with Arm partnership
Target: Mobile, embedded, and edge devices; Cortex-M55/M85 with Helium; Ethos-U NPUs
Key features: PyTorch-native workflow; selective operator builds; KleidiAI/CMSIS-NN integration; TOSA backend for Arm accelerators; ahead-of-time compilation
Best for: PyTorch-centric teams; projects targeting newer Arm cores with vector extensions; unified mobile+embedded deployment
Maintainer: Jon Nordby (open source)
Target: Any platform with a C compiler; extremely constrained MCUs (Cortex-M0+)
Key features: Classical ML focus (Random Forest, Decision Trees, MLP, Gaussian Naive Bayes, k-NN); codegen from scikit-learn; minimal dependencies; MicroPython bindings
Runtime size: 1-20KB typical
Best for: Classical ML models; extremely resource-constrained devices; projects where neural networks are overkill
Maintainer: Community (originally from Arm)
Target: Arm Mbed ecosystem, Cortex-M
Key features: Lightweight C++11 runtime; memory-safe tensor arena; type-safe operator binding
Status: Under active development but less mature than alternatives
Best for: Mbed-based projects; learning/research applications
4. Compiler Frameworks
These tools focus on model optimization and code generation across multiple backends.
Maintainer: Apache Software Foundation
Target: CPUs, GPUs, NPUs, FPGAs, and microcontrollers
Key features: Auto-tuning for target hardware; Relay IR for graph optimization; AOT compilation for bare-metal; Zephyr RTOS integration; hardware-agnostic optimization
Best for: Teams needing cross-platform deployment; research projects; squeezing maximum performance from specific hardware
Maintainer: Arm
Target: Cortex-M processors
Key features: Highly optimized neural network kernels; DSP/SIMD acceleration; INT8/INT16 quantized operations; foundation for other frameworks (TFLite Micro, STM32Cube.AI use it internally)
Best for: Custom inference engines; maximum performance on Cortex-M; framework developers
5. FPGA-Targeted Tools
When MCU performance isn't sufficient, FPGAs offer custom hardware acceleration.
Maintainer: Fast Machine Learning collaboration
Target: Xilinx (Vivado/Vitis HLS), Intel FPGAs
Key features: Converts Keras/PyTorch/ONNX to HLS; sub-microsecond latency; fully pipelined inference; custom precision (down to binary/ternary); extensive quantization support
Best for: Ultra-low-latency applications (particle physics, high-frequency trading); real-time image/signal processing; applications requiring custom bit-widths
Hardware Tier Mapping
Framework choice depends heavily on your target hardware capabilities. Here's how the frameworks map to hardware tiers:
| Hardware Tier | Characteristics | Viable Frameworks | Typical Applications |
|---|---|---|---|
| Nano Cortex-M0/M0+/M3 |
8-64KB SRAM No FPU/DSP <100MHz |
emlearn, hand-coded | Threshold detection, simple classifiers, decision trees |
| Micro Cortex-M4F/M33 |
128-512KB SRAM DSP extensions 80-200MHz |
TFLite Micro, STM32Cube.AI, NanoEdge AI, emlearn, Edge Impulse | Keyword spotting, gesture recognition, vibration analysis, anomaly detection |
| Performance Cortex-M7/M55/M85 |
512KB-2MB SRAM Helium MVE 400MHz+ |
ExecuTorch, TFLite Micro, TVM, STM32Cube.AI, NXP eIQ | Person detection, image classification, audio scene analysis |
| NPU-Equipped Ethos-U, Neural-ART |
Dedicated accelerator 100+ GOPS |
ExecuTorch + Ethos backend, STM32Cube.AI (N6), NXP eIQ (Neutron) | Real-time object detection, face recognition, complex audio |
| FPGA | Custom logic Parallel execution Sub-μs latency |
hls4ml, TVM (experimental) | Particle physics triggers, high-frequency trading, real-time video |
Application Domain Mapping
Different frameworks have strengths in different application domains. Here's guidance based on sensor modality and use case:
Vibration / Condition Monitoring
Industrial predictive maintenance, motor health, bearing analysis.
- First choice: NanoEdge AI Studio (designed for this; synthetic anomaly generation)
- Alternatives: Edge Impulse (good signal processing blocks), emlearn (if classical ML suffices), STM32Cube.AI (if using STM32)
Audio / Acoustic Sensing
Keyword spotting, sound classification, acoustic anomaly detection.
- First choice: Edge Impulse (excellent audio preprocessing), TFLite Micro (mature KWS support)
- Alternatives: ExecuTorch (for PyTorch models), STM32Cube.AI
Vision / Camera Systems
Person detection, object classification, quality inspection.
- First choice: STM32Cube.AI (STM32N6 with NPU), NXP eIQ (i.MX with GPU/NPU), ExecuTorch (Ethos-U)
- Alternatives: TFLite Micro (simpler models), hls4ml (FPGA for ultra-low latency)
Motion / IMU / Activity Recognition
Gesture detection, fall detection, activity classification.
- First choice: Edge Impulse (strong IMU support), NanoEdge AI Studio
- Alternatives: emlearn (if model is simple), TFLite Micro
Sensor Fusion / Navigation
IMU+GPS fusion, state estimation, localization.
- First choice: Custom solution with CMSIS-NN kernels, ExecuTorch
- Note: Many fusion tasks are better served by classical Kalman filters than neural networks
Control Systems
Motor control, robotics, real-time estimation.
- Caution: ML in control loops requires bounded WCET. Consider ML as observer/estimator only.
- If proceeding: emlearn (deterministic), hand-optimized CMSIS-NN, hls4ml (FPGA)
Decision Framework
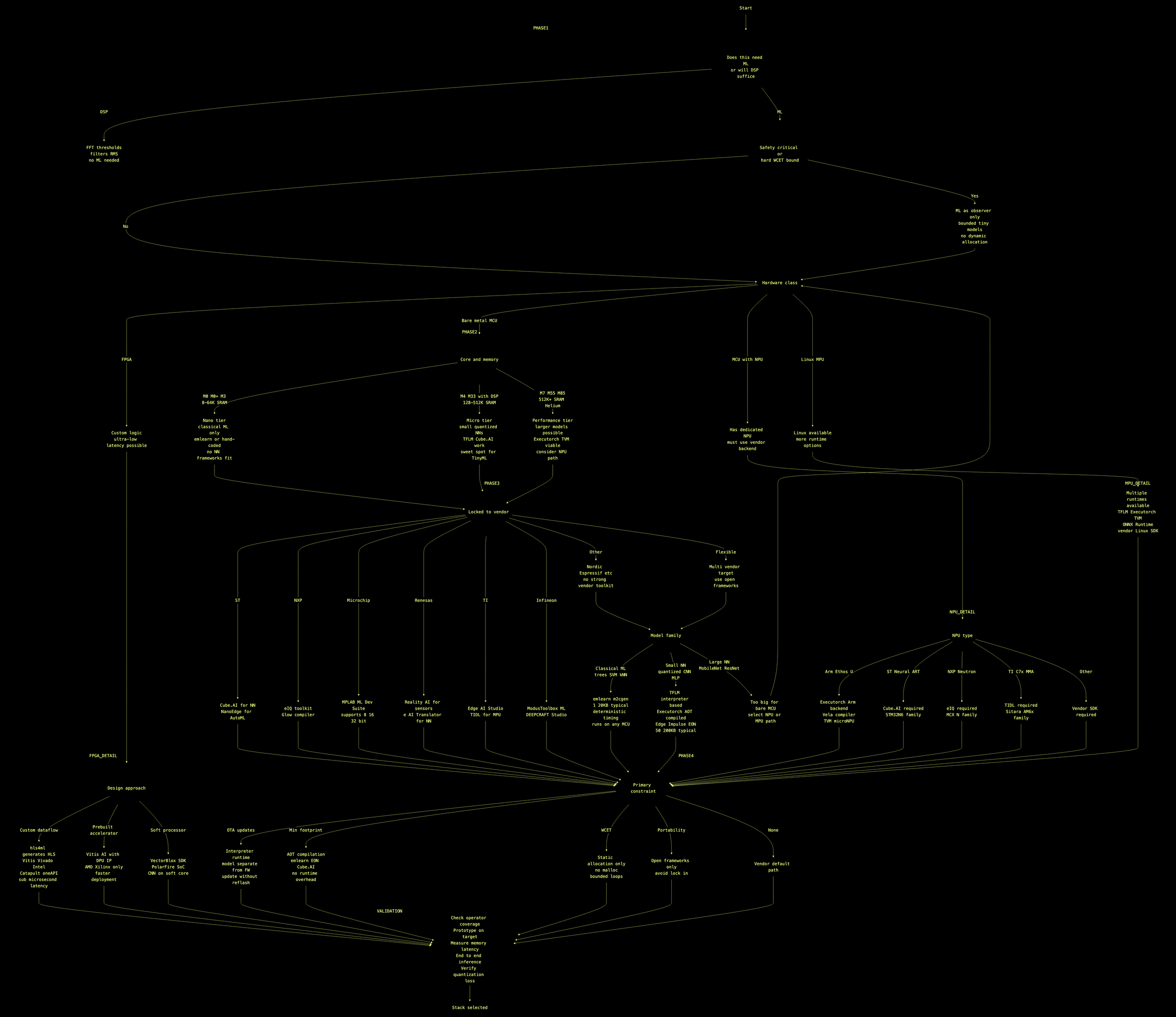
Use this structured approach to narrow your framework selection:
Step 1: Do You Need ML?
Many embedded sensing problems are better solved with classical DSP. If you can describe your trigger condition without using words like "similar to" or "like a," DSP may suffice. FFT + threshold detection, RMS calculations, zero-crossing analysis—these are deterministic, explainable, and consume far fewer resources.
Step 2: What's Your Hardware?
- Already selected silicon: Start with the vendor toolkit (STM32Cube.AI, NXP eIQ)
- Flexibility in silicon selection: Consider portable frameworks (TFLite Micro, ExecuTorch, emlearn)
- NPU available: Use framework with NPU backend support
- FPGA available: Consider hls4ml for sub-microsecond requirements
Step 3: What's Your Model Family?
- Classical ML (trees, linear, SVM): emlearn, NanoEdge AI Studio, STM32Cube.AI (via ONNX)
- Small neural networks (tiny CNN, 1D CNN, small MLP): TFLite Micro, STM32Cube.AI, Edge Impulse, ExecuTorch
- Larger networks (MobileNet, ResNet): ExecuTorch, NXP eIQ, TVM—requires Cortex-A or NPU
Step 4: What's Your Team's Expertise?
- No ML expertise: NanoEdge AI Studio, Edge Impulse
- TensorFlow background: TFLite Micro, STM32Cube.AI
- PyTorch background: ExecuTorch
- scikit-learn background: emlearn
- FPGA/HLS expertise: hls4ml
Step 5: Production Requirements
- OTA model updates needed: TFLite Micro (interpreter allows model replacement)
- Minimum footprint priority: AOT compilers (STM32Cube.AI, emlearn, Edge Impulse EON)
- Deterministic timing required: AOT compilers, emlearn, hand-optimized CMSIS-NN
- Multi-platform deployment: TFLite Micro, ExecuTorch, TVM
Framework Comparison Matrix
| Framework | Type | Min Target | Input Formats | Open Source | OTA Updates | NPU Support |
|---|---|---|---|---|---|---|
| TFLite Micro | Interpreter | Cortex-M3 | .tflite | Yes | Yes | Via delegates |
| ExecuTorch | AOT | Cortex-M4 | PyTorch | Yes | Limited | Ethos-U, TOSA |
| STM32Cube.AI | AOT | Cortex-M0+ | .tflite, ONNX, .h5 | No (free) | Relocatable | Neural-ART |
| NXP eIQ | Mixed | i.MX RT | TF, ONNX, PyTorch | Partial | Yes | Neutron NPU |
| NanoEdge AI | AutoML+AOT | Cortex-M0+ | Raw sensor data | No (free) | No | No |
| Edge Impulse | Platform+AOT | Cortex-M0+ | Raw data, TF, ONNX | SDK only | Yes | Via backends |
| emlearn | AOT codegen | Any C target | scikit-learn | Yes | No | No |
| TVM/microTVM | Compiler | Cortex-M | TF, PyTorch, ONNX | Yes | No | Multiple |
| CMSIS-NN | Kernel library | Cortex-M | N/A (kernels) | Yes | N/A | No |
| hls4ml | HLS codegen | FPGA | Keras, PyTorch, ONNX | Yes | Bitstream | N/A (is the NPU) |
Common Pitfalls
Starting with the framework, not the requirements. Engineers often pick TFLite Micro because it's popular, then discover their model needs operators it doesn't support, or the interpreter overhead is unacceptable. Start with feasibility analysis: can your model fit? Does the framework support the operators you need?
Ignoring the operator coverage problem. Every framework supports a different subset of neural network operators. A model that trains perfectly in PyTorch may fail to deploy because GlobalAveragePooling3D isn't supported. Check operator coverage before training, not after.
Underestimating integration effort. Vendor toolkits trade portability for integration ease. If you're already using STM32CubeMX, STM32Cube.AI drops into your workflow. If you're not, the learning curve may exceed that of a more portable option.
Over-engineering the solution. A Random Forest from emlearn, taking 5KB Flash and running in 100μs, may outperform a neural network taking 100KB and 50ms for your vibration classification task. Match the solution complexity to the problem.
Forgetting about updates. If you ship 10,000 devices and later need to improve model accuracy, can you update them? Interpreter-based runtimes allow model-only updates. AOT compilation means full firmware reflash. Plan for the product lifecycle.
Emerging Trends
NPU democratization. Dedicated neural processing units are appearing in mainstream MCUs (STM32N6, NXP MCX-N). Frameworks are racing to support these accelerators. ExecuTorch's Ethos-U backend and STM32Cube.AI's Neural-ART support are early examples.
PyTorch ecosystem convergence. ExecuTorch 1.0 signals PyTorch's serious push into embedded. Teams already using PyTorch for training will increasingly deploy via ExecuTorch rather than converting to TensorFlow.
AutoML maturation. NanoEdge AI Studio's synthetic data generation and Edge Impulse's expanding model zoo suggest these platforms are moving beyond prototyping toward production viability.
On-device learning. NanoEdge AI and some research frameworks support learning directly on the MCU—adapting to specific equipment or users without cloud retraining. This remains niche but addresses real deployment challenges.
The Bottom Line
There is no universally best embedded ML framework. The right choice depends on your hardware, model requirements, team expertise, and production constraints. Use this taxonomy to narrow options quickly:
- Filter by hardware tier compatibility
- Filter by model family support
- Filter by production requirements (OTA, footprint, timing)
- Choose based on team expertise and ecosystem fit
The most expensive mistake isn't choosing a suboptimal framework—it's discovering incompatibility three months into development. Validate your choice with a minimal prototype on target hardware before committing. Run actual inference, measure actual memory, verify actual latency. The framework comparison matrix and decision tree that follows this article should help you avoid that costly discovery.